1. Http 이란?
Http는 (Hyper Text Transfer Protocol)의 약자, Protocol은 통신을 원활하게 수용할 수 있도록 하는 통신 규약이고,
웹 브라우저와 웹 서버가 HTML로 작성된 웹 페이지나 파일 등등을 주고받기 위한 통신규약이다.
2. Http 통신이란?
클라이언트가 서버에 요청 메세지를 보내고 요청에 대해 서버가 응답 메세지를 반환, 통신 규약에 맞게 데이터를 주고받는 것 -> 그림

requset / response 구조 -> 그림

3. Body: 해당 요청의 실제 내용. 주로 Body를 사용하는 메소드는 POST다.
ex) 로그인 시에 서버에 보낼 요청의 내용
Body: {
"user_email": "jun.choi@gmail.com"
"user_password": "wecode"
}
가장 많이 사용되는 Body 의 데이터 타입은 JSON(JavaScript Object Notation)
특징
비연결지향적인 단방향 통신
클라이언트가 요청을 보내는 경우에만 서버가 응답하는 단방향 통신, 서버로부터 응답을 받은 후에는 연결이 바로 종료
서버는 응답 메세지를 반환한 후에 초기 상태로 돌아감, 이때 서버는 클라이언트의 상태를 저장하지 않는다.
즉, 상태가 없는 프로토콜이다. 여기서 상태가 없다라는 말은 데이터를 주고 받기 위한 각각의 데이터 요청이 서로 독립적으로 관리됨, 이전 데이터 요청과 다음 데이터 요청이 서로 관련이 없음.
예를 들어 클라이언트가 "밥 먹으러 갈래?"고 서버에게 요청해서 "좋아" 라는 응답을 잘 받아왔지만 그 다음번에 "몇시가 편해?"라고 요청을 한다면 서버는 이 전에 "밥먹으러 갈래?" 라는 요청을 기억하지 못하기 때문에 클라이언트가 원하는 응답을 줄 수가 없게 되는 것 -> 그림
이러한 특징 덕분에 서버는 세션과 같은 별도의 추가 정보를 관리하지 않아도 되고, 다수의 요청 처리 및 서버의 부하를 줄일 수 있는 성능 상의 이점이 생깁니다.
HTTP 프로토콜은 전송 계층 프로토콜로 TCP를 사용하고 네트워크 계층 프로토콜로 IP를 사용하는 것이 일반적,
이 두 계층을 합쳐서 TCP/IP라는 이름으로 부르고, TCP/IP에서는 IP주소를 사용해서 통신할 컴퓨터를 결정, 그리고 포트 번호를 사용해서 그 컴퓨터의 어떤 프로그램과 통신할지를 결정. HTTP에서는 기본적으로 80번 포트를 사용.
TCP/IP 설명
TCP : 애플리케이션이 전송한 데이터를 그 형태 그대로 상대방에게 확실하게 전달함
TCP가 하는 일 : 포트 번호를 이용해서 데이터 전송, 연결 생성, 데이버 보증과 재전송 제어, 흐름 제어와 폭주 제어,
IP : 지정한 대상 서버까지 전달받은 데이터를 전해지는 것
IP가 하는 일 : IP주소를 이용해서 최종 목적지에 데이터 전송, 라우팅
TCP/IP 4계층 모델

Transport Layer Protocol
- TCP, UDP는 Transport Layer의 통신 프로토콜입니다.
- Transport Layer는 logical connection을 기반으로 프로세스 간의 통신이 일어나는 레이어입니다.
- End point간 신뢰성 있는 데이터 전송을 담당하는 계층입니다.
- 신뢰성: 데이터를 순차적이고 안정적으로 전달
- 전송: 포트번호에 해당하는 프로세스에 데이터를 전달
- flow control을 담당
- congestion control을 담당
3.TCP의 개념
Transmission Control Protocol 는 전송을 제어하는 프로토콜로, 신뢰도가 높은 데이터 전송을 가능하게 합니다.
연결기반, 신뢰성
Application으로부터 받은 Message에 header를 붙여 encapsulation하여 세그먼트로 만들어 logical channel로 전송합니다.
데이터 전송단위: Segment

1. 연결지향적
2. 3 way handshaking(연결 설정)과 4 way handshaking(연결 해제) 작업으로 인한 신뢰성 보장
3 way-handShake를 하는 이유
- 데이터의 정확한 전송을 보장하기 위함
->
3 way handshaking

[STEP 1]
A클라이언트는 B서버에 접속을 요청하는 SYN 패킷을 보낸다. 이때 A클라이언트는 SYN 을 보내고 SYN/ACK 응답을 기다리는SYN_SENT 상태가 되는 것이다.
[STEP 2]
B서버는 SYN요청을 받고 A클라이언트에게 요청을 수락한다는 ACK 와 SYN flag 가 설정된 패킷을 발송하고 A가 다시 ACK으로 응답하기를 기다린다. 이때 B서버는 SYN_RECEIVED 상태가 된다.
[STEP 3]
A클라이언트는 B서버에게 ACK을 보내고 이후로부터는 연결이 이루어지고 데이터가 오가게 되는것이다. 이때의 B서버 상태가 ESTABLISHED 이다.
위와 같은 방식으로 통신하는것이 신뢰성 있는 연결을 맺어 준다는 TCP의 3 Way handshake 방식이다.
4 way handshaking
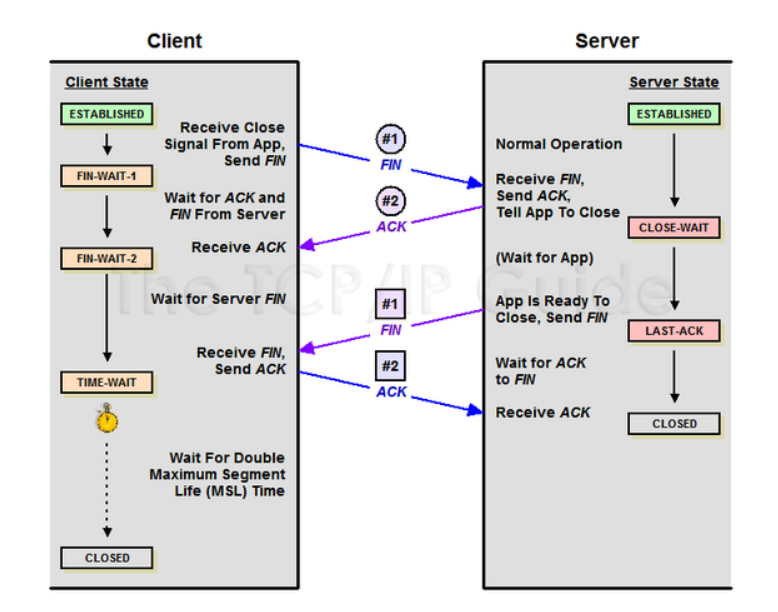
3. 순서 보장
4. 흐름제어 (Flow control)
데이터 처리 속도를 조절하여 수신자의 버퍼 오버플로우를 방지
-> 송신하는 곳에서 많은 양의 데이터를 빠르게 보내 수신하는 곳에서 문제가 일어나는 것을 막는다.
5. 혼잡제어 (Congestion control)
네트워크 내의 패킷 수가 넘치게 증가하지 않도록 방지
-> 정보의 소통량이 과다하면 패킷을 조금만 전송하여 혼잡 붕괴 현상이 일어나는 것을 막는다.
HTTP프로토콜이 TCP를 사용한다고하는데
HTTP통신은 비연결 통신인데 어떻게 연결지향적인 TCP프로토콜을 사용하는 건가요?
-> HTTP 통신이 비 연결 통신이라는건 이전 요청과 다음 요청이 연결되어있지 않다는 의미입니다. 하나의 요청/응답 안에서는 연결된 상태로 통신하는게 맞습니다.
HTTP 프로토콜이 TCP 기반으로 동작한다는 것은 하나의 요청-응답 내에서의 이야기를 말하는 겁니다.
TCP 기반으로 만들어진 프로토콜이 HTTP

OSI 7 계층 그림과 TCP/IP 4계층 그림

OSI 7 계층으로 나눈 이유가 무엇인가? 통신이 일어나는 과정을 단계 별로 파악할 수 있기 때문이다. 흐름을 한 눈에 알아보기 쉽고, 사람들이 이해하기 쉽고, 7단계 중 특정한 곳에 이상이 생기면 다른 단계의 장비 및 소프트웨어를 건드리지 않고도 이상이 생긴 단계만 고칠 수 있다.
4.UDP의 개념
개발 배경
User Datagram Protocol
비연결형 서비스를 지원하는 전송계층 프로토콜로써 인터넷상에서 서로 정보를 주고받을 때 정보를 보낸다는 신호나 받는 다는 신호절차를 거치지 않고 보내는 쪽에서 일방적으로 데이터를 전달하는 통신 프로토콜이다
데이터그램이란 독립적인 관계를 지니는 패킷
UDP가 하지 않는 것 = TCP는 하는 것.
- 연결 셋업 / 종료 (Connection setup/teardown)
- 수신 완료했다고 알리기 (Acknoledgement)
- 재전송 (Retransmission)
- Fragmentation
- 혼잡 제어 (Congestion Control)
- 순서대로 보내기 (In-order delivery)
- PMTU discovery
연결없음, 신뢰안함
Application layer로부터 받은 Message를 세그먼트 단위로 쪼개지 않고, UDP 헤더만 붙여 데이터그램 단위로 처리합니다.
전송 단위: Datagram

UDP 헤더에는 목적지주소, 데이터순서, checksum과 실데이터만 포함되고, 확인응답이 없기 때문에 용량이 가볍고 송신속도가 빠르다.
->

하지만 확인응답을 하지 못하기 때문에 신뢰도가 TCP보다 떨어지게 된다.
사용자 데이터그램 프로토콜(User Datagram Protocol)
IP 프로토콜에 PORT, 체크섬 필드 정보만 추가된 단순한 프로토콜입니다.
앞서 TCP 특징과 비교해보면 신뢰성은 낮지만 3 way handshake 방식을 사용하지 않기 때문에 TCP와 비교해 빠른 속도를 보장합니다.
HTTP3는 UDP를 사용하며 이미 여러 기능이 구현된 TCP보다는 하얀 도화지처럼 커스터마이징이 가능하다는 장점이 있습니다. 아직 TCP와 UDP의 차이는, 좋은 기능이 다 들어있는 무거운 라이브러리와 필요한 기능만 들어있는 가벼운 라이브러리로 비교할 수 있겠습니다.
(체크섬(checksum)은 중복 검사의 한 형태로, 오류 정정을 통해, 공간(전자 통신)이나 시간(기억 장치) 속에서 송신된 자료의 무결성을 보호하는 단순한 방법.)
1. 실시간(Real-time)
제약 조건이 거의 없고 TCP에 비해 매우 빨라, 실시간 전송이 필요한 부분에 대해서 많이 사용됩니다.
* 사용처 : 인터넷 전화, 스트리밍 등등
2. 간단한 트랜잭션(Simple transactions)
같은 전송 계층인 프로토콜 TCP와 비교하자면, TCP 는 Setup과 종료, ACK 가 필수불가결하기 때문에
복잡한 transaction이 요구됩니다. 하지만, UDP는 그딴거 다 필요없다!! 😎
* 사용처 : DNS(반드시 UDP이용), DHCP, SNMP 등등
3. 멀티캐스트 / 브로드캐스트 가능
TCP는 전송측과 수신측이 서로 검증이 완료가 돼야 보냅니다.
Point-to-point 방식으로 작동하는 TCP는 멀티캐스트, 브로드캐스트 전송이 모두 불가능합니다.
UDP 만이 가능하죠.
* 사용처 : IPTV
5. TCP와 UDP의 차이

비교하고 앞에서 설명한 특징(연결지향형/비연결지향형, 순서보장/안됨, 상대적으로 느림/빠름, 신뢰성있는 데이터 전송(안정적)/데이터전송보장X, 사용하는 곳 비교)들 비교 그리고 앞에서 다루지 않은 특징들도 있다고 알려줌
1. 인증
인증은 사용자의 신원을 검증하는 행위로서 보안 프로세스에서 첫 번째 단계입니다.
자주 사용하는 인증 프로세스 중 예시는
- 비밀번호. 사용자 이름과 비밀번호는 가장 많이 사용되는 인증 요소입니다. 사용자가 데이터를 올바르게 입력하면 시스템은 아이덴티티가 유효하다고 판단하고 액세스를 허용합니다.
- 생체인식. 사용자가 시스템에 액세스하기 위해 지문이나 망막 스캔을 제출합니다.
2. 인가
인가는 사용자에게 특정 리소스나 기능에 액세스할 수 있는 권한을 부여하는 프로세스를 말합니다.
대표적으로 예시로 네이버 카페 등급을 들 수 있습니다. 등업을 할 때마다 새로운 게시판을 열람하거나 글이나 댓글을 작성할 수 있는 권한이 생기는 것을 인가의 예시로 들수 있습니다.
0. 쿠키와 세션 사용하는 이유
HTTP 프로토콜의 특성이자 약점을 보완하기 위해서 쿠키 또는 세션을 사용합니다.
기본적으로 HTTP 프로토콜 환경은 "connectionless, stateless"한 특성을 가지기 때문에 서버는 클라이언트가 누구인지 매번 확인해야합니다. 이 특성을 보완하기 위해서 쿠키와 세션을 사용하게됩니다.
1. 쿠키
쿠키란?
- 쿠키는 클라이언트(브라우저) 로컬에 저장되는 키와 값이 들어있는 작은 데이터 파일입니다.
- 사용자 인증이 유효한 시간을 명시할 수 있으며, 유효 시간이 정해지면 브라우저가 종료되어도 인증이 유지된다는 특징이 있습니다.
- 쿠키는 클라이언트의 상태 정보를 로컬에 저장했다가 참조합니다.
- 클라이언트에 300개까지 쿠키저장 가능, 하나의 도메인당 20개의 값만 가질 수 있음, 하나의 쿠키값은 4KB까지 저장합니다.
- Response Header에 Set-Cookie 속성을 사용하면 클라이언트에 쿠키를 만들 수 있습니다.
- 쿠키는 사용자가 따로 요청하지 않아도 브라우저가 Request시에 Request Header를 넣어서 자동으로 서버에 전송합니다.
쿠키의 구성 요소
- 이름 : 각각의 쿠키를 구별하는 데 사용되는 이름
- 값 : 쿠키의 이름과 관련된 값
- 유효시간 : 쿠키의 유지시간
- 도메인 : 쿠키를 전송할 도메인
- 경로 : 쿠키를 전송할 요청 경로
쿠키의 동작 방식
- 클라이언트가 페이지를 요청
- 서버에서 쿠키를 생성
- HTTP 헤더에 쿠키를 포함 시켜 응답
- 브라우저가 종료되어도 쿠키 만료 기간이 있다면 클라이언트에서 보관하고 있음
- 같은 요청을 할 경우 HTTP 헤더에 쿠키를 함께 보냄
- 서버에서 쿠키를 읽어 이전 상태 정보를 변경 할 필요가 있을 때 쿠키를 업데이트 하여 변경된 쿠키를 HTTP 헤더에 포함시켜 응답
쿠키의 사용 예
- 방문 사이트에서 로그인 시, "아이디와 비밀번호를 저장하시겠습니까?"
- 쇼핑몰의 장바구니 기능
- 자동로그인, 팝업에서 "오늘 더 이상 이 창을 보지 않음" 체크, 쇼핑몰의 장바구니
2. 세션
세션이란?
- 세션은 쿠키를 기반하고 있지만, 사용자 정보 파일을 브라우저에 저장하는 쿠키와 달리 세션은 서버 측에서 관리합니다.
- 서버에서는 클라이언트를 구분하기 위해 세션 ID를 부여하며 웹 브라우저가 서버에 접속해서 브라우저를 종료할 때까지 인증상태를 유지합니다.
- 물론 접속 시간에 제한을 두어 일정 시간 응답이 없다면 정보가 유지되지 않게 설정이 가능 합니다.
- 사용자에 대한 정보를 서버에 두기 때문에 쿠키보다 보안에 좋지만, 사용자가 많아질수록 서버 메모리를 많이 차지하게 됩니다.
- 즉 동접자 수가 많은 웹 사이트인 경우 서버에 과부하를 주게 되므로 성능 저하의 요인이 됩니다.
- 클라이언트가 Request를 보내면, 해당 서버의 엔진이 클라이언트에게 유일한 ID를 부여하는 데 이것이 세션 ID입니다.
세션의 동작 방식
- 클라이언트가 서버에 접속 시 세션 ID를 발급 받음
- 클라이언트는 세션 ID에 대해 쿠키를 사용해서 저장하고 가지고 있음
- 클라리언트는 서버에 요청할 때, 이 쿠키의 세션 ID를 같이 서버에 전달해서 요청
- 서버는 세션 ID를 전달 받아서 별다른 작업없이 세션 ID로 세션에 있는 클라언트 정보를 가져와서 사용
- 클라이언트 정보를 가지고 서버 요청을 처리하여 클라이언트에게 응답
세션의 특징
- 각 클라이언트에게 고유 ID를 부여
- 세션 ID로 클라이언트를 구분해서 클라이언트의 요구에 맞는 서비스를 제공
- 보안 면에서 쿠키보다 우수
- 사용자가 많아질수록 서버 메모리를 많이 차지하게 됨
세션의 사용 예
- 로그인 같이 보안상 중요한 작업을 수행할 때 사용
3. 쿠키와 세션 차이
- 쿠키와 세션은 비슷한 역할을 하며, 동작원리도 비슷합니다. 그 이유는 세션도 결국 쿠키를 사용하기 때문입니다.
- 가장 큰 차이점은 사용자의 정보가 저장되는 위치입니다. 때문에 쿠키는 서버의 자원을 전혀 사용하지 않으며, 세션은 서버의 자원을 사용합니다.
- 보안 면에서 세션이 더 우수하며, 요청 속도는 쿠키가 세션보다 더 빠릅니다. 그 이유는 세션은 서버의 처리가 필요하기 때문입니다.
- 보안, 쿠키는 클라이언트 로컬에 저장되기 때문에 변질되거나 request에서 스니핑 당할 우려가 있어서 보안에 취약하지만 세션은 쿠키를 이용해서 sessionid 만 저장하고 그것으로 구분해서 서버에서 처리하기 때문에 비교적 보안성이 좋습니다.
- 라이프 사이클, 쿠키도 만료시간이 있지만 파일로 저장되기 때문에 브라우저를 종료해도 계속해서 정보가 남아 있을 수 있다. 또한 만료기간을 넉넉하게 잡아두면 쿠키삭제를 할 때 까지 유지될 수도 있습니다.
- 반면에 세션도 만료시간을 정할 수 있지만 브라우저가 종료되면 만료시간에 상관없이 삭제됩니다. 예를 들어, 크롬에서 다른 탭을 사용해도 세션을 공유됩니다. 다른 브라우저를 사용하게 되면 다른 세션을 사용할 수 있습니다.
- 속도, 쿠키에 정보가 있기 때문에 서버에 요청시 속도가 빠르고 세션은 정보가 서버에 있기 때문에 처리가 요구되어 비교적 느린 속도를 가집니다.
'개념 정리' 카테고리의 다른 글
| NginX 이해하기 (+ Web Server , WAS) (0) | 2022.08.30 |
|---|---|
| 깃(Git) 개념(버전 관리 시스템 - VCS)과 명령어 정리(CLI) (0) | 2022.08.16 |
| DTO, VO 개념과 차이점 (0) | 2022.07.18 |
| 로드 밸런싱(Load Balancing) 개념 정리 (0) | 2021.12.17 |


